

BERT(Bidirectional Encoder Representations from Transformers, BERT)는 2018년 구글이 개발한 자연어 처리 신경망 구조이며, 기존의 단방향 자연어 처리 모델들의 단점을 보완한 양방향 자연어 처리 모델이다. 트랜스포머를 이용하여 구현되었으며, 방대한 양의 텍스트 데이터로 사전 훈련된 언어모델이다.

BERT의 기본 구조는 위와 같이 transformer의 encoder를 쌓아올린 구조이다. BERT는 이 구조를 기반으로 다음와 같은 Task를 학습시킨다.
- 다음 문장 예측 (Next Sentence Prediction, NSP)
- 문장에서 가려진 토큰 예측 (Maked Language Model, MLM)
위와 같은 학습을 거친 모델로 다른 자연어 처리 학습을 수행하면 빠른 속도로 좋은 결과를 낸다. 파인 튜닝 (하이퍼 파라미터를 재조정)을 통해 최대 성능을 낸 기존 사례들을 참고해서 사전 학습된 BERT위에 분류를 위한 신경망을 한층 추가하는 방식으로 최대의 정확도를 낸다.
BERT Input
BERT에 들어가는 데이터의 인풋 형식은 아래의 그림과 같다.
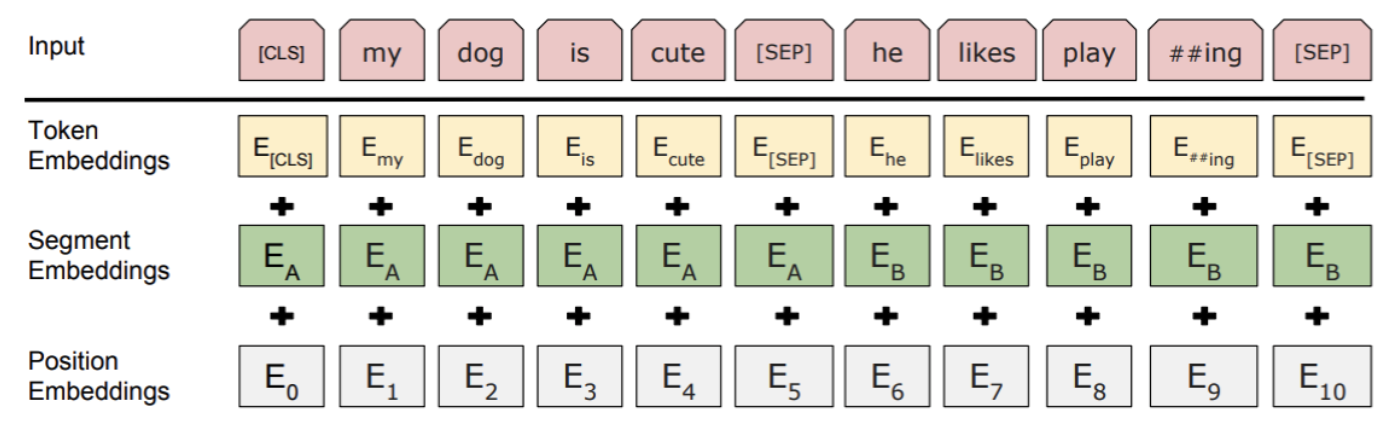
우선 Segment embedding을 위해 문장을 BERT의 입력 형식에 맞게 변환시킨다. 문장의 시작은 [CLS], 문장의 끝은 [SEP]으로 표시한다.

두번째로는 한 문장에 있는 단어들에 대해 tokenization을 진행한다. 예를 들어 '우리들'이라는 단어의 경우 '우##', '#리#', '##들'로 tokenization을 진행한다.

마지막으로는 Positional embedding인데, 각 token들에 대해 고유의 아이디를 부여한다. token이 존재하지 않는 자리에 한해서는 0으로 채워준다.

BERT OUTPUT
1. Next Sentence Prediction (NSP) - 다음 문장 예측

BERT는 두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련시킨다. 한 문장의 맨 첫번째 토큰인 [CLS]의 출력부에서 입력받은 첫 문장이 두번째 문장과 이어지는지 판별하는 것으로 학습시킨다.
2. Masked Language Model (MLM) - 마스크드 언어 모델

BERT의 토큰 별로 개별적인 Softmax Layer + Fully connected layer를 거쳐 가려진 token에 대해 단어를 예상시키는 학습을 진행한다. Mask되지 않은 토큰에 대한 학습까지 병행하며 Mask된 토큰에 대한 예상 학습 정확도를 올린다.
참고:
1:brunch.co.kr/@tristanmhhd/12
BERT란 무엇인가?
- Attention Is All You Need! | 위의 그림에서와 같이 BERT는 구글에서 개발한 자연어 처리 신경망 구조이며 기본구조는 아래의 Transformer라는 구조에서 Encoder를 적층시켜 만들었다. BERT는 이 구조를 기반
brunch.co.kr
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
'Data Science > ML&AI' 카테고리의 다른 글
| [NLP] Word Embedding with Lookup table - nn.Embedding() (0) | 2021.06.03 |
|---|---|
| [NLP] Embedding - fastText란? (0) | 2021.04.14 |
| [NLP] NLP 사전 훈련 변천사: 1. Word Embedding & ELMo (0) | 2021.03.17 |
| [머신러닝] Undersampling과 Oversampling이란? (0) | 2020.09.20 |
| [Classification] 오차행렬, 재현율, 정밀도와 F1 Score (0) | 2020.09.18 |