
레이블이 불균형한 분포를 가진 데이터 세트를 학습 시, 이상 레이블을 가지는 데이터 건수가 매우 적어 제대로 된 유형의 학습이 어렵다. 반면에 정상 레이블을 가지는 데이터 건수는 매우 많아 일방적으로 정상 레이블로 치우친 학습을 수행하며, 제대로 된 이상 데이터 검출이 어렵다.
이러한 문제점을 보완하고 적절한 학습 데이터를 확보하는 방안이 필요한데, 언더 샘플링과 오버 샘플링은 이러한 방안의 대표적 예시이다!
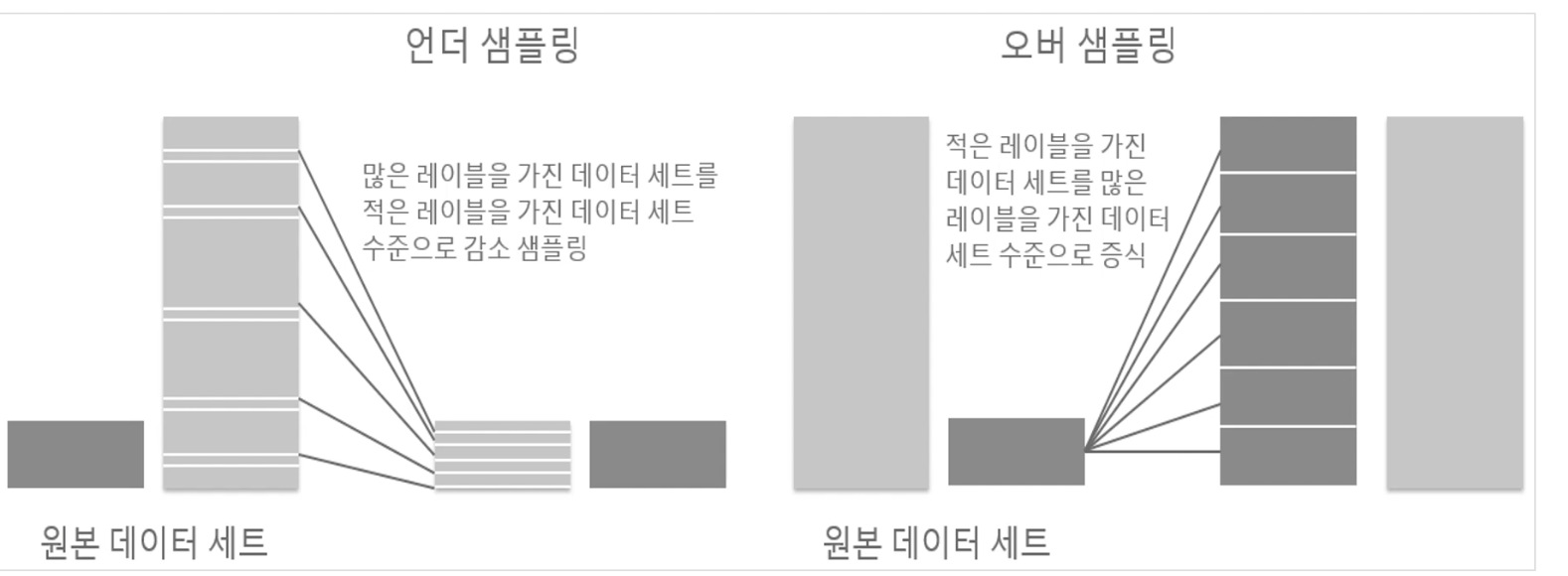
언더 샘플링은 높은 비율을 차지하던 클래스의 데이터 셋의 개수를 줄이는 방법으로 데이터 불균형을 해소하는 아이디어이다. 하지만 학습에 사용되는 데이터 수가 줄어들기 때문에 학습의 성능이 줄 수 있으므로 주의해야한다.
오버 샘플링은 낮은 비율 클래스의 데이터를 증식하여 학습을 위한 충분한 데이터를 확보하는 방법이다. 데이터셋의 개수가 줄지 않는다는 점에서 언더샘플링보다 나은 접근방식일 수 있다. 이 방식은 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식하는 방법인데 대표적으로 SMOTE 이론이 있다.
SMOTE (Synthetic Minority Over-Sampling Technique)
SMOTE는 적은 데이터 셋에 있는 개별 데이터들의 K Nearest Neighbor를 찾아서 이 데이터와 K개 이웃들의 차이를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터들을 생성하는 방식이다. 아예 동일한 데이터를 복사하여 증식시키는 것은 의미가 없기 때문에 적은 클래스의 데이터 셋의 근접 이웃을 기점으로 데이터를 새로 증식시킨다.
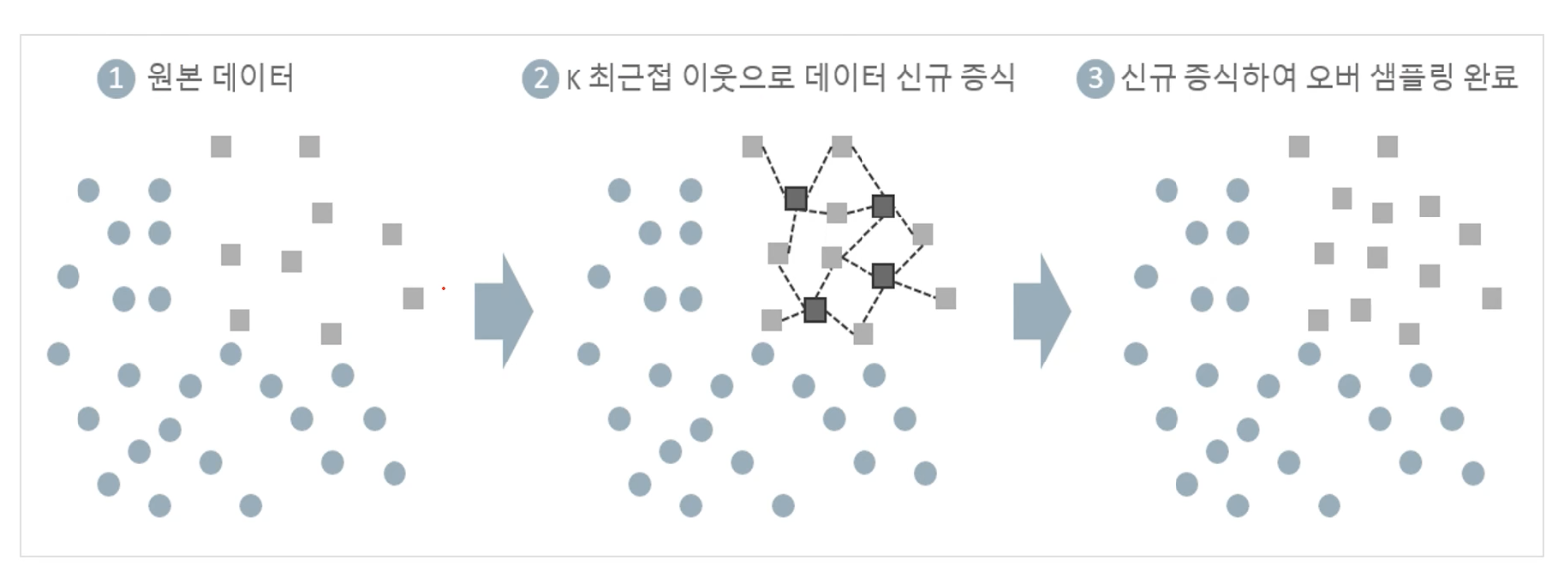
자료 참고 & 이미지 출처: 인프런: 파이썬 머신러닝 완벽 가이드 4강 분류학습
'Data Science > ML&AI' 카테고리의 다른 글
| [NLP] Word Embedding with Lookup table - nn.Embedding() (0) | 2021.06.03 |
|---|---|
| [NLP] Embedding - fastText란? (0) | 2021.04.14 |
| [NLP] BERT란? - 자연어 처리 모델 알아보기 (0) | 2021.03.20 |
| [NLP] NLP 사전 훈련 변천사: 1. Word Embedding & ELMo (0) | 2021.03.17 |
| [Classification] 오차행렬, 재현율, 정밀도와 F1 Score (0) | 2020.09.18 |